Use-case benchmarks
The best model is the one that ships your work.
We don't sell you the cheapest token or chase a single contested leaderboard number. srooter benchmarks by developer use case and routes each request to the model that maximises productivity — automatically, behind one endpoint. Below is how we route, and the evidence behind it.
“Implement or refactor a feature across many files”
Coding agent
Everyday multi-file coding routes to GLM-5.2 — srooter’s substantive default, which topped our first-party build benchmark (8/8, the cleanest UI of five models). The highest-stakes work escalates to Claude Opus + the council; you can pin any model per request. We never silently downgrade a coding turn for budget alone.
srooter routes to
GLM
Z.ai
Productivity outcome
First-try PR correctness — fewer review round-trips
Evidence · First-party build benchmark
GLM-5.2 8/8 (best of 5) · Claude Opus 4.8 7/8 · same app, browser-verified
srooter benchmarks ↗Measured — agent-build benchmark · verified July 2026
Nine-model coding build-off
One agent, one full app — email login, a three-panelist "council" plus synthesis, persistent threads, and full-text search. Two axes: (1) 8 browser acceptance checks (does it work?), (2) a hand-graded 0–5 polish score of the finished build (is it any good?). Eight of nine passed all 8 checks, so pass/fail saturates — polish is what separates them. Each model pinned (served verbatim, not routed); iterate-to-pass, capped. Times are wall-clock; tokens are output. Rows sorted by polish, then efficiency.
| Model | Acceptance | Polish | Build | Iters | Wall | Out tokens | Notes |
|---|---|---|---|---|---|---|---|
| kimi-k3 | 8/8 | Pass | 2 | 1208s | 36.9k | NEW · Moonshot flagship — 5/5 polish in the FEWEST iterations (2); the cheapest 5/5 by build cost | |
| claude-opus | 8/8 | Pass | 3 | 652s | 40.8k | Fastest 5/5 (652s) — top polish, quick | |
| claude-fable-5 | 8/8 | Pass | 3 | 763s | 47.5k | Top polish — dark theme, role subtitles, graceful stub note | |
| gpt-5.6-sol | 8/8 | Pass | 3 | 2196s | 73.3k | Frontier flagship — top polish, but 3–4× slower / ~2× tokens | |
| gpt-5.5 | 8/8 | Pass | 2 | 519s | 28.0k | Named personas + role tags, clean dark theme | |
| glm-5.2 | 7/8 | Pass | 4 | 602s | 34.7k | Only miss: panelist-count check; strong dark-theme build | |
| gpt-5.6-terra | 8/8 | Pass | 2 | 1194s | 43.2k | GPT-5.6 balanced tier (≈ GPT-5.5) — styled config banner | |
| deepseek-pro | 8/8 | Pass | 1 | 505s | 31.7k | Fastest — 8/8 in one pass, but barer UI (raw markdown leak) | |
| kimi-2.7-code | 8/8 | Pass | 3 | 772s | 30.7k | Passed, but the barest build — flat cards, no role design |
- Six of eight built a working app to a perfect 8/8 — so pass/fail can’t rank them. We hand-graded each finished build 0–5 on layout, role design, and graceful-degradation. That’s where the real spread lives.
- Polish tracks model class: Opus, Fable, and Sol shipped 5/5 builds (color-coded panelist roles, graceful “no API key” fallbacks); DeepSeek and Kimi passed the same checks but shipped barer UIs (3/5, 2/5). The 8/8 ceiling hid exactly this difference.
- The value leader is new: Kimi K3 hits the same 5/5 polish as Opus / Fable / Sol, but at ~$3.60 / build — half of Opus, a third of Fable — and reached 8/8 in the fewest iterations (2). Its one trade-off is speed (1208s; the reasoning-max flagship is slower than Opus’s 652s). No single winner — route top-craft where quality matters to K3 (cheapest 5/5) or Opus (fastest 5/5), and high volume to fast-and-good-enough (DeepSeek / GPT-5.5).
Methodology. A distinct July 2026 run — nine models incl. Kimi K3 (vs the June “Five models” block below) on an improved harness: empty-turn failover + tool-loop fixes since resolved June’s GPT-5.5 build failure, and a per-iteration watchdog + port cleanup were added. Each model was pinned (served verbatim, not routed); iterate-to-pass capped at 5 rounds; times are wall-clock, tokens are output. The 0–5 polish score is a subjective, hand-graded review of each finished build — layout, panelist-role design, and graceful degradation on missing config — from identical-viewport screenshots + source, not an automated metric. Acceptance is run-to-run variable on the cosmetic panelist-count check (why Opus and GLM-5.2 can land 7/8 one run, 8/8 another). These are this run’s numbers and do not supersede the separate June block.
The pricing view · cost to build the same app
The pricing view — what polish costs
Same app, cost to build it on each model at list price (constant ~1M input + 40k output — the build-off average). Pips are the hand-graded polish. The question a router answers per request: the cheapest model that clears your quality bar.
| Model | Polish | Cost to build → | List · in / out per 1M |
|---|---|---|---|
| deepseek-proCheapest that ships | $0.47 | $0.44 / $0.87 | |
| glm-5.2Best 4/5 value | $1.14 | $1.10 blended | |
| gpt-5.6-lunaCost tier (not built) | — | $1.24 | $1.00 / $6.00 |
| kimi-2.7-codePays more for less | $1.77 | $1.70 blended | |
| gpt-5.6-terraBalanced | $3.10 | $2.50 / $15.00 | |
| kimi-k3Cheapest 5/5 · flagship | $3.60 | $3.00 / $15.00 | |
| claude-opusFastest 5/5 | $6.00 | $5.00 / $25.00 | |
| gpt-5.6-solFrontier ceiling · 3–4× slower | $6.20 | $5.00 / $30.00 | |
| gpt-5.5Flagship price, 4/5 build | $6.20 | $5.00 / $30.00 | |
| claude-fable-5Premium 5/5 | $12.00 | $10.00 / $50.00 |
Kimi K3 reset the top tier: same 5/5 polish as Opus / Fable / Sol at $3.60 / build — the cheapest 5-star of the nine (half of Opus, a third of Fable). The other flagships are a price band for a slower or pricier path to the same bar: gpt-5.6-sol costs the same as Opus but runs 3–4× slower; gpt-5.5 charges flagship rates for a 4/5 build. Pick the cheapest model that clears your bar — that routing, per request, is srooter.
List price, uncached. Real agentic builds cache the input prefix (~10× cheaper in), so absolute $ run lower — the ordering holds. GLM & Kimi shown at the gateway’s blended config rate (no public in/out split).
Measured — first-party benchmark · verified June 2026
One-shot full-app build
Build a complete app in a single autonomous pass: email login, a multi-perspective "council" answering with three panelists plus a synthesis, persistent threads, and full-text search. Same spec, same harness; measured on quality, cost, and speed.
| Metric | Claude Opus 4.8 (direct) | Claude Fable-5 (direct) | srooter (governed routing) |
|---|---|---|---|
| Acceptance criteria (browser E2E) | 8/8 | 8/8 | 8/8 |
| Type-checks & builds (npm run build) | Pass | Pass | Pass |
| Build cost (measured) | $3.02 | $3.05 | ≈$1–3 |
| Wall-clock time | 7.96 min | 5.95 min | 10–16 min |
| Tokens processed | 2.43M | 1.06M | 3.6–4.5M |
| Agentic turns | 43 | 39 | 53–66 |
| UX polish (reviewed from screenshots) | 4.5/5 | 5/5 ★ | 4/5 |
- Per-token price is the wrong number: Fable-5 costs ~2× Opus per token but used ~2.3× fewer tokens — identical total (~$3), 25% faster. Optimize tokens-to-done.
- srooter delivered the same 8/8, build-passing app through governed cheap-model routing at roughly a half to a third of the direct-frontier cost — trading wall-clock speed for cost + governance (budgets, audit, policy).
- srooter cost is measured at the gateway audit: client-side meters price routed backends at the requested model’s rates and can overstate real spend by 5–10×.
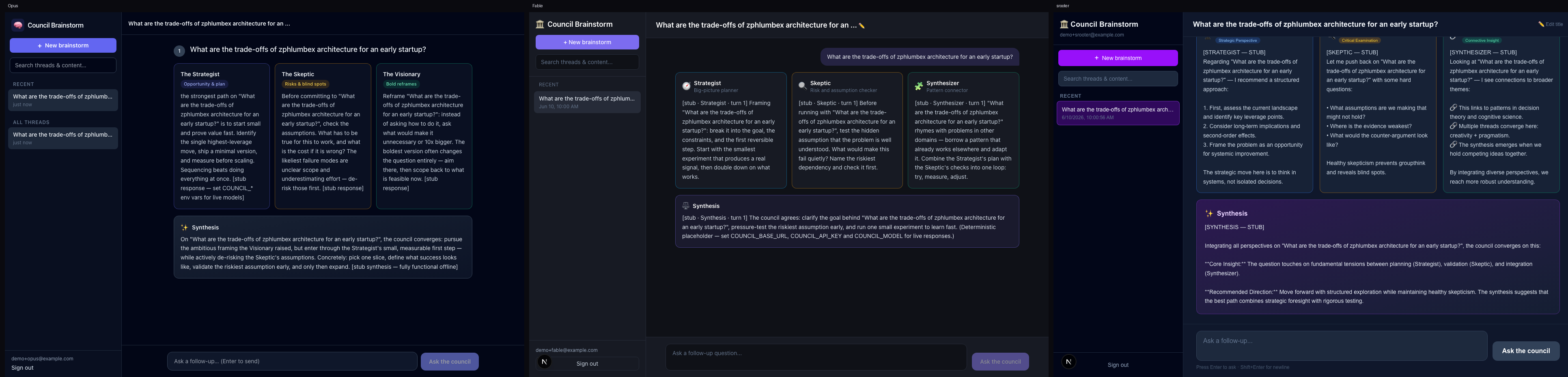
Claude Fable-5 vs Opus 4.8: the token-efficiency story
- Per-token price
- Fable-5 ≈ 2.0× Opus ($10/$50 vs $5/$25 per M in/out)
- Tokens to finish the same app
- 1.06M vs 2.43M — Fable used 2.3× fewer
- Net result
- Total cost within 1% (~$3 each) · Fable 25% faster (5.95 vs 7.96 min) · fewer turns (39 vs 43)
- Quality
- Both 8/8 in a real browser; Fable produced the most polished UI of the three builds (role-labelled panelist cards, cleanest hierarchy)
A stronger model that one-shots in fewer turns can be cheaper AND faster than a “cheaper” model that needs more attempts. This is the signal srooter routes on — tokens-to-done, not sticker price per token.
Methodology. One spec, one harness: each configuration got a single autonomous `claude -p` run (no retries, no human help) against the same written spec with 8 acceptance criteria. Quality was verified by a headless Playwright E2E driving every criterion in a real browser plus `npm run build`; cost and tokens come from the run artifacts and the gateway audit; UX was reviewed from identical-viewport screenshots. June 2026.
Measured — multi-model benchmark · verified June 2026
Five models, same app — coding & routing tiers
Every model built the same Next.js 15 + TypeScript + Tailwind app ("Council Brainstorm") end-to-end through srooter-agent — our own CLI — iterating until an 8-point Playwright acceptance suite passed (capped at 4 rounds). Models were pinned so the gateway served each one verbatim. Scored on accuracy, speed, output tokens, cost, and UI polish.
Coding tier — full app build
| Model | Acceptance | Build | Out tokens | Wall | Cost | UI polish |
|---|---|---|---|---|---|---|
| GLM-5.2Z.ai | 8/8 | Pass | 54.5k | 22.3 min | ≈$0.12 | Best — dark, color-coded |
| DeepSeek-V4 ProDeepSeek | 8/8 | Pass | 43.5k | 7.8 min | ≈$0.04 | Clean — best value |
| Claude Opus 4.8Anthropic | 7/8 | Pass | 41.0k | 11.4 min | ≈$25.73 | Most refined UI |
| Kimi 2.7Moonshot | 7/8 | Pass | 22.2k | 7.7 min | ≈$0.06 | Functional, unstyled |
| GPT-5.5OpenAI | 0/8 | Fail | 0 | — | — | Build failed |
Routing tier — small bounded tasks (all 100% correct → speed decides)
| Model | Accuracy | Per task | Read |
|---|---|---|---|
| Cerebras | 100% | 1.0s | Fastest — sub-second, perfect |
| Kimi-highspeed | 100% | 1.5s | Nearly as fast, perfect |
| Gemini | 100% | 4.7s | Leanest tokens, still fast |
| DeepSeek-V4 Pro | 100% | 5.8s | Accurate, mid-speed |
| MiniMax-2.5 | 100% | 6.2s | Accurate, mid-speed |
| GLM-5.2 | 100% | 15.3s | Heavy — a coding model, not a routing one |
- No single "best" model: GLM-5.2 won on build quality (only 8/8 with the cleanest UI), DeepSeek-V4 Pro won on value (also 8/8, 2.9× faster, lowest cost), Cerebras won the routing tier on speed. That spread is the entire reason a routing layer exists.
- The cheaper model won outright: GLM-5.2 built the same app and scored higher than Claude Opus (8/8 vs 7/8) — at a small fraction of the cost. On a like-for-like basis (GLM’s input tokens weren’t metered, so its $0.12 is output-only) that’s ~25× cheaper than Opus’s ≈$25.73; on output tokens alone, far more. Per-token sticker price is the wrong number.
- GPT-5.5 failed through our converted serving path (empty turns); with a model pinned, the gateway’s empty-turn failover is off, so it surfaced raw — keep failover on for it. A real reliability finding, not a billing blip.
Methodology. Run entirely on our own stack — srooter gateway + srooter-agent CLI (dogfooded). Accuracy via Playwright (8 acceptance criteria); UI polish judged from identical-viewport screenshots. Cost is list-price-from-tokens (the truer number is the gateway audit); some models’ input tokens weren’t metered by the client, so their cost is output-only and understated — compare directionally, not to the cent. Models pinned via x-srooter-pin so each served verbatim instead of being routed. June 2026.
Use-case × model fit
| Use case | Claude Opus4.8 | GLM5.2 | MiniMax-M2M2 | MiniMax-M3M3 | Gemini3.1 Pro | DeepSeekV3.2 | Cerebrasgpt-oss-120b | Qwen332B |
|---|---|---|---|---|---|---|---|---|
| Coding agent | routed | |||||||
| Whole-repo / long context | routed | |||||||
| Architecture & security review | routed | |||||||
| Quick edits & housekeeping | routed | |||||||
| Bulk extraction & classification | routed | |||||||
| Hard debugging & reasoning | routed |
Models reference
The models srooter routes across, with versions and where each shines. SWE-bench Verified figures are external evidence (approximate — see note).
Anthropic
Frontier coding, architecture & security judgment
- Context:
- 200K (1M beta)
- SWE-bench:
- ~88.6%
Z.ai
srooter’s substantive coding default — top build quality at a fraction of frontier cost
- Context:
- ~200K
- SWE-bench:
- First-party: 8/8 build (best of 5)
MiniMax
Near-frontier coding at a fraction of the cost
- Context:
- ~205K
- SWE-bench:
- ~80% (open-weight leader)
MiniMax
Whole-repo / long-context work without truncation
- Context:
- 1M
- SWE-bench:
- —
Multimodal, bulk extraction, grounded research
- Context:
- 1M+
- SWE-bench:
- ~80.6%
DeepSeek
Strong reasoning & debugging, very low cost
- Context:
- 128K
- SWE-bench:
- ~73%
Cerebras
srooter’s trivial-tier default — fastest paid inference for commits & housekeeping
- Context:
- 128K
- SWE-bench:
- —
Alibaba
Local/cheap fallback for trivial turns
- Context:
- 256K
- SWE-bench:
- —
External benchmarks are shown as evidence, sourced and dated (verified June 2026); treat them as approximate. SWE-bench Verified is known to be partly contaminated (OpenAI moved to SWE-bench Pro in early 2026) — which is exactly why we lead with use-case fit, not one number. The fit ratings are srooter's routing recommendations, not measured scores.